
Noel Röhrig
Softwareentwickler auf Rädern 🚎
30.01.2025 | 4 min Lesezeit
Bruno als dateibasierter API-Client


Als Softwareentwickler arbeiten wir regelmäßig mit APIs. Das übliche Kommunikationsprotokoll ist hier HTTP - und um das Senden und Empfangen von HTTP-Requests zu vereinfachen, gibt es eine Bandbreite an HTTP-Clients. Als ich meine Ausbildung 2017 begonnen habe, war das non-plus-ultra hierfür "Postman". Es war übersichtlich, simpel, kostenlos und straightforward - installieren und einfach HTTP-Requests verschicken. Leider ist Postman dem üblichen Weg der Enshittification gefolgt - so sehr dass man sich mittlerweile dreimal überlegen muss ob man sich durch die Nutzung von Postman nicht sogar ein security risk ins Haus holt.
Cloudbasierte HTTP-Clients
Zuerst einmal klingt es absurd, dass ein HTTP-Client eine Cloud Anbindungen erzwingt und teilweise die Requests selber sogar aus der Cloud abfeuert. Die Hersteller argumentieren hier mit den Möglichkeiten durch Synchronisation, Kollaboration und komplexen Umgebungsverwaltungen. Und das ist soweit auch nicht falsch - zum Beispiel müssen sich neue Mitarbeiter nur registrieren und können sich daraufhin in ein "gemachtes Nest" setzen. Alle Requests die das Team regelmäßig nutzt, alle Services und alle Secrets sind mit der Cloud synchronisiert.
Genau hier liegt auch direkt der erste Knackpunkt. Werden alle Requests direkt synchronisiert, werden unweigerlich auch secrets, API-keys und andere sensible Daten an den Anbieter des HTTP-"Clients" gesendet. Damit öffnet sich eine ganze Bandbreite an security risks: Konten einzelner Nutzer können geknackt werden, ein Leak direkt beim Anbieter oder schlichte Anwenderfehler können zu öffentlichen Workspaces führen.
Darüber hinaus ist auch der Kostenpunkt nicht zu vernachlässigen. Die Anbieter von HTTP-Clients versuchen auch deshalb immer mehr auf die Cloud zu setzen, weil lokale offline Clients sich schlechter verkaufen lassen. Cloudanwendungen mit Nutzerverwaltung, Workspace Synchronisation und Browserzugriff mit Requests die von den Anbieterservern verschickt werden, lassen sich gut verkaufen. Ob der ganze Ansatz notwendig oder gar Sinnvoll ist, ist zweitrangig. Würde man einem Entwickler aus dem Jahr 2010 erzählen, dass es in 15 Jahren üblich ist, ein teures Abonnement für einen HTTP-Client zu bezahlen, würde man für verrückt gehalten.
Open-source to the rescue
Der zunehmende Login-Zwang und die Kosten(-fallen) sorgen dafür, dass viele Entwickler nach Alternativen suchen. Glücklicherweise gibt es mittlerweile mehrere lokale, offline-fähige und dateibasierte Lösungen. Dazu gehören ThunderClient oder .http files.
Ich persönlich habe mich mit Bruno angefreundet. Das Projekt ist open-source und entstand aus Frust über cloudbasierte HTTP-Clients und dem Unternehmen unterliegt ein Manifest welches, wenn man ihm Glauben schenkt, diametral entgegen zukünftiger Enshittification steht.
Bruno

Bruno führt eine eigene Markup-Sprache namens .bru ein. In einer solchen .bru Datei stehen dann alle relevanten Angaben zu einem HTTP-Request. Von der URL, payload bis hin zu API keys und secrets. Dieser dateibasierte Ansatz, gibt den Entwicklern die volle Kontrolle über ihre HTTP-Collection.
Darauf aufbauend lassen sich die Requests aus drei Umgebungen ausführen:
- Bruno CLI
- Bruno Desktop Client
- Bruno VS Code Extension
Darüber hinaus lassen sich .bru Dateien parametrisieren, testen, Assertions ausführen und mit Environment Variablen aus eigenen .env Dateien speisen. Mit seinem Team kann man Collections einfach über übliche Versionskontrollen (sprich: git) teilen. Hier gelten dann die üblichen Gefahren mit Versionskontrollen: .env Dateien dürfen nicht eingecheckt werden, sonst landen Secrets oder API-keys in irgendeinem Repo.
Legt man über den Bruno Desktop Client eine neue Collection an, unternimmt seine Einstellungen bezüglich Requests, Authentication und co., legt die Anwendung direkt die passenden Dateien an:
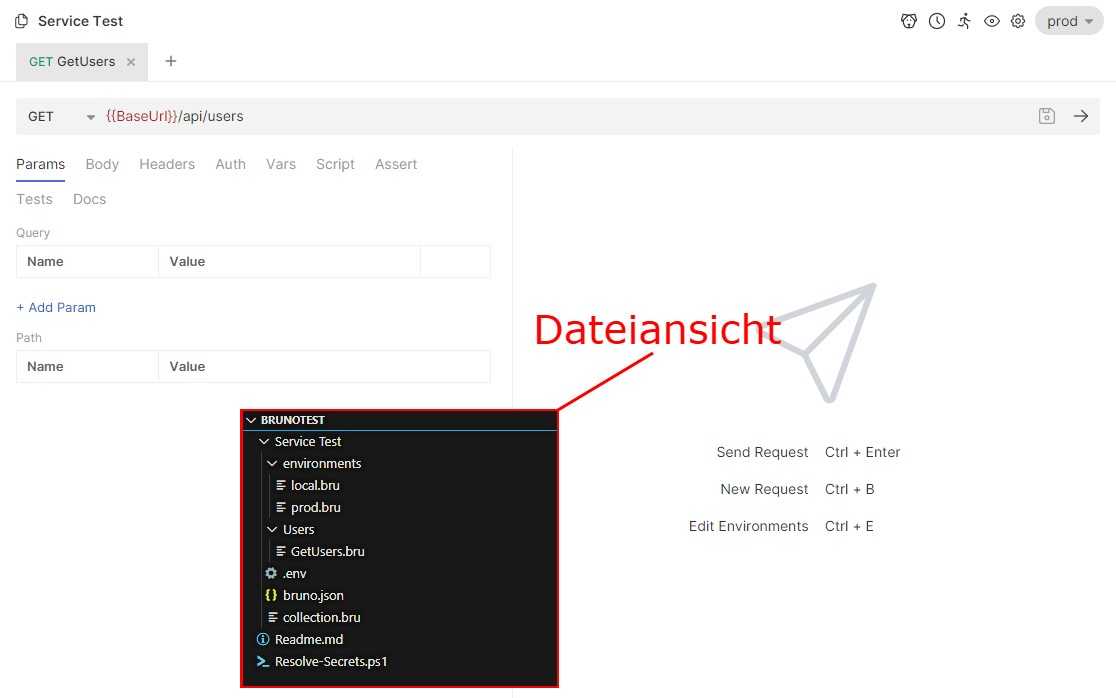
Nach ausfüllen von Environment Variablen und Secrets, sehen die Dateien wie folgt aus:

Da man die .env Datei auf keinen Fall in die Versionskontrolle schicken sollte, kann es dazu kommen, dass neue Entwickler sich erst mühsam alle Secrets und API-keys zusammensuchen müssen. In meinem Projekt haben wir die zugehörigen Variablen alle in KeyVaults gespeichert. Das Resolve-Secrets.ps1 script zieht die Werte aus den KeyVaults und speichert diese in den zugehörigen .env Dateien.
Fazit
Nachdem ich jahrelang Postman genutzt habe, musste ich vor einer Weile feststellen, dass ich in meinem Arbeitsalltag vor HTTP-Requests abgeschreckt reagierte. Die ursprüngliche "Kurz mal den request ausprobieren"-Mentalität die mit HTTP-Clients wie Postman einherging, wurde durch das jonglieren von Accounts, Workspaces, Cloudsyncs und Secrets dermaßen getrübt, dass ich mich selbst erwischt habe GET Requests lieber direkt über den Browser auszuführen.
Seitdem ich Bruno benutze, macht es mir wieder Spaß, HTTP-Collections aufzubauen. Bruno zeigt, dass ein leistungsfähiger HTTP-Client keine Cloud-Abhängigkeit braucht – und dass wir als Entwickler Alternativen zu überladenen, kommerziellen Lösungen haben.
PS: Die Tatsache, dass mein Hund Bruno heißt, hatte absolut keinen Einfluss auf diesen Blogbeitrag – versprochen.