

Daniel Schaber
Softwareprojekt Allrounder
03.07.2024 | 10 min Lesezeit
Bulk-Import in CosmosDB mit Stored Procedures



Es gibt Momente beim Entwickeln von großen Software-Projekten, in denen die ursprüngliche Architektur nicht mehr den neuen Anforderungen standhalten kann. Da gilt es flexibel zu sein und hin und wieder die einzelnen Komponenten anzupassen. Dies ist einfacher, wenn man von Beginn an dafür sorgt, dass Komponenten austauschbar sind. Jedoch kann es selbst dann auf dem Weg zur robusteren und performanteren Architektur plötzlich zu Herausforderungen kommen, die man so nicht vorhergesehen hat. In unserem Fall haben sich Features einzelner Komponenten gegenseitig ausgehebelt. So konnten wir den Bulk-Import in unsere Datenbank nicht ohne weiteres mit einer ServiceBus Queue kombinieren. Wie wir gestartet haben und wie wir die Herausforderung letztendlich gelöst haben, möchte ich hier kurz beschreiben.
Die Infrastruktur zu Beginn
Unsere Datenbank ist die CosmosDB von Microsoft Azure. Eine Web-API bietet die Möglichkeit einen Import von Daten durchzuführen. Diese können in einem vorgegebenen JSON- oder XML-Format übergeben werden. Dabei können große Mengen neu importiert, geupdated oder gelöscht werden. Das Dokument für die CosmosDB wird im Code auf Basis der Importdaten und erweiterten Parametern erstellt und mit einem Upsert in die CosmosDB geschrieben. Beim Löschen werden eindeutige Ids verwendet, um die entsprechenden Dokumente zu löschen.
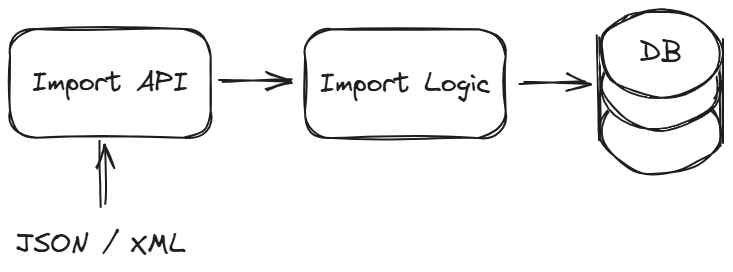
Too many requests
Wer Erfahrung mit der CosmosDB hat, der weiß, dass es sinnvoll ist sich geeignete Partitionen für seine Daten zu überlegen. Ein sogenannter PartitionKey hilft bei vielen Transaktionen, andere Partitionen nicht unnötig zu belasten. Einfach gesagt: ist eine Partition unter hoher Last und kann nicht mehr alle Anfragen bearbeiten, sind andere Partitionen davon unberührt. Die Wahl eines geeigneten PartitionKey ist entscheidend, um "Hot Partitions" zu vermeiden, die zu Lastproblemen führen können.
"code":429, "message":"Request rate is large. More Request Units may be needed, so no changes were made."Der Fehler 429 kann darauf hindeuten, dass entweder kein (geeigneter) PartitionKey verwendet wurde oder die Anfragen so zahlreich sind, dass zu wenig Request Units (RUs) zur Verfügung stehen. RUs ist die Einheit anhand der Microsoft die Kosten für die CosmosDB berechnet. Gehen wir nun davon aus, dass kein besserer PartitionKey gefunden werden kann und die Zahl der Transaktionen tatsächlich sehr hoch ist, dann gäbe es die Option, die RUs zu erhöhen und höhere Kosten in Kauf zu nehmen. Eine weitere Möglichkeit ist ein Retry Mechanismus zu implementieren, der beim Fehler 429 der Cosmos DB eine kurze Verschnaufpause gönnt und es dann noch einmal versucht.
_DefaultRetryPolicy = Policy.Handle<CosmosException>(ex => ex.StatusCode == HttpStatusCode.TooManyRequests)
.WaitAndRetryAsync(_RetryCount, i => TimeSpan.FromSeconds(_RetrySleepSeconds));Aber je nach Datenmenge kann auch hier ein Limit erreicht werden, das die CosmosDB an ihre Grenzen bringt.
Für unsere Anwendung brauchten wir zeitnah eine bessere Lösung. Glücklicherweise hat Microsoft mit dem Azure Cosmos DB .NET SDK v3 für die API für NoSQL den Support von Bulk-Execution released.
AllowBulkExecution
Bulk-Execution in Cosmos DB ist eine Methode, um eine große Anzahl von Datenoperationen (wie Einfügen, Aktualisieren oder Löschen) effizient und schnell durchzuführen. Mit Bulk-Execution kann man diese Operationen bündeln und gleichzeitig ausführen, was die Verarbeitungsgeschwindigkeit erheblich erhöht und die Kosten senkt.
Vorteile der Bulk-Execution
- Schnelligkeit: Erheblich schneller als einzelne Operationen.
- Kosteneinsparung: Weniger Request Units (RUs) pro Operation, was die Kosten senkt.
- Effizienz: Bessere Nutzung der Netzwerk- und Rechenressourcen.
Die Implementierung kann wie folgt aussehen:
CosmosClientOptions options = new CosmosClientOptions() { AllowBulkExecution = true };
CosmosClient cosmosClient = new CosmosClient(connectionString, options);Damit waren größere Mengen an Transaktionen ohne Probleme zu bewältigen.
Die Infrastruktur ändert sich
Nach einiger Zeit mussten wir weitere Änderungen an der Infrastruktur vornehmen. Wir speichern nun die Importdaten in einem Cloudspeicher und haben die Processing-Logik von der API losgelöst. Eine ServiceBus-Queue mit entsprechender Empfänger-Logik kümmert sich nun unabhängig um den Import der Daten, indem es diese aus dem Cloudspeicher lädt, verarbeitet und speichert.
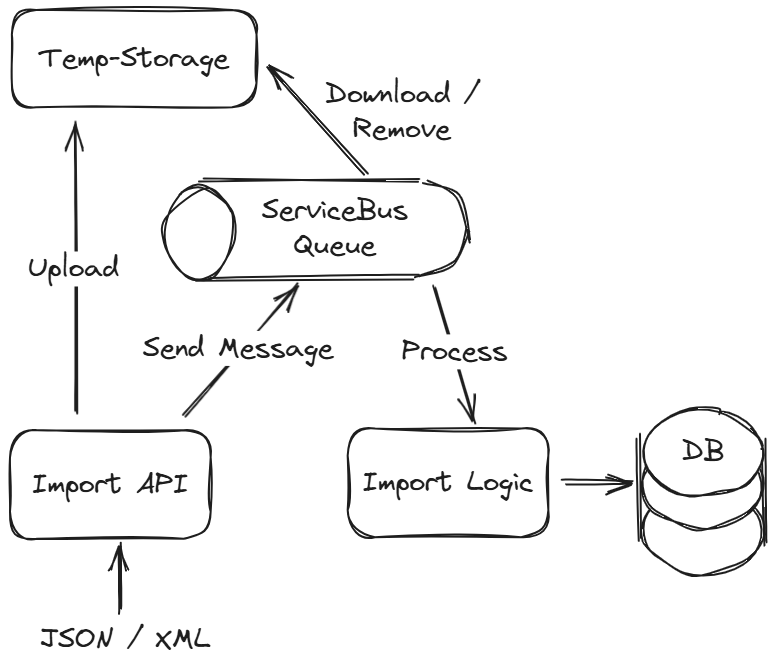
Warum haben wir das gemacht?
-
Skalierbarkeit: Durch die Verwendung einer ServiceBus-Queue kann das System besser mit einer hohen Anzahl von Anfragen umgehen, da die Nachrichten in der Queue gespeichert und nach und nach verarbeitet werden können. Dies verhindert eine Überlastung der Import-Logik und der Datenbank.
-
Fehlerisolierung: Wenn ein Fehler in der Import-Logik auftritt, bleiben die Nachrichten in der Queue erhalten und können später erneut verarbeitet werden, sobald das Problem behoben ist. Dies sorgt für eine höhere Zuverlässigkeit und Fehlertoleranz.
-
Asynchrone Verarbeitung: Das System kann asynchron arbeiten, was bedeutet, dass die Import-API sofort antworten kann, ohne auf die vollständige Verarbeitung der Daten warten zu müssen. Dies verbessert die Reaktionszeit der API.
-
Datenhaltung und Wiederverwendung: Temporäre Speicherung ermöglicht die Speicherung von großen Dateien oder Datenmengen, die nicht direkt verarbeitet werden können, und stellt sicher, dass sie verfügbar sind, bis sie vollständig verarbeitet wurden. Bei einem Fehler bleiben die Importdaten weiterhin vorhanden und können untersucht werden.
-
Gewährleistung der Reihenfolge: Nachrichten in einer Queue können so konfiguriert werden, dass sie in der Reihenfolge abgearbeitet werden, in der sie eingegangen sind. So kann sichergestellt werden, dass keine Nachricht übersprungen oder Daten in der falschen Reihenfolge geschrieben werden. Dies ist besonders wichtig, wenn die Reihenfolge der Datenimporte entscheidend für die Konsistenz der Datenbank ist.
Natürlich gibt es auch Nachteile dieser Architektur, wie unter anderem Komplexität, Kosten, Latenz und komplexere Fehlerbehandlung sowie Monitoring. Die Fehlerbehandlung wird komplexer, da die Nachrichten in der Queue erneut verarbeitet werden müssen und es Mechanismen geben muss, um Nachrichten, die wiederholt fehlschlagen, zu erkennen und zu behandeln. Die Überwachung und das Logging des Systems werden anspruchsvoller, da mehr Komponenten überwacht werden müssen und die Fehlerdiagnose schwieriger sein kann.
Beim Azure Service Bus ermöglicht das Einstellen von Sessions, dass Nachrichten mit demselben Session-ID-Wert in der Reihenfolge verarbeitet werden, in der sie gesendet wurden. Dies stellt sicher, dass zusammengehörige Nachrichten sequentiell und in der richtigen Reihenfolge verarbeitet werden. Um Sessions zu verwenden, muss der Sender die Session-ID jeder Nachricht festlegen, und der Empfänger muss eine Session-Receiver-Instanz erstellen, um die Nachrichten dieser Session sequentiell abzurufen.
Böses Erwachen
Wir waren sehr zufrieden mit dieser Architektur, bis eines Tages mehrere große Datenimporte erfolgten und wir folgenden Fehler in unseren Logs erblickten:
Microsoft.Azure.WebJobs.ServiceBus.Listeners.ServiceBusListener
Consistency, Session, Properties, and Triggers are not allowed when AllowBulkExecution is set to true.Kurz: ServiceBus Trigger, mit Sessions aktiv, sind nicht kompatibel mit AllowBulkExecution. Diese Einschränkungen bestehen, um die Integrität und Effizienz von Massenoperationen sicherzustellen. Die gleichzeitige Unterstützung von Bulk-Operationen, Sessions und Triggern würde die Komplexität der Implementierung und Wartung der Datenbank erheblich erhöhen. Es würde erfordern, dass das System gleichzeitig hohe Leistung und strenge Konsistenz gewährleistet, was technisch herausfordernd und ressourcenintensiv ist.
Allerdings ist ohne Bulk-Execution ein Import dieser Datenmengen nicht mehr in angemessener Zeit möglich.
Eine Tasse Kaffee ☕
Zeit für einen Kaffee! Etwas Abstand und noch einmal in Ruhe über die Architektur nachdenken. Während ich an meiner Tasse schlürfte sprach ich mit Michael über die eben aufgetretene Problematik. Interessanterweise hatte er einen sehr konkreten Vorschlag. In seinem Projekt arbeitet er ebenfalls mit der CosmosDB und war gerade dabei "Stored Procedures" zu implementieren. Er meinte, dass diese mein Problem eventuell lösen könnten.
Stored Procedures
Stored Procedures sind uns auch in unserem Projekt nicht fremd, dennoch kam mir selbst der Gedanke nicht, dass sie die Möglichkeit bieten die Trennung der Nachrichtenverarbeitung so von der Datenspeicherung zu trennen, das Konsistenz gewährleistet wird. Sie können Transaktionen ausführen, und dabei sicherstellen, dass komplexe Operationen entweder vollständig oder gar nicht ausgeführt werden. Außerdem werden sie direkt auf dem Server ausgeführt, was die Latenzzeiten reduziert, da weniger Netzwerkaufrufe erforderlich sind und die Logik in der Nähe der Daten ausgeführt wird. Da die Verarbeitung innerhalb der Datenbank erfolgt, wird die Belastung des Nachricht-Konsumenten reduziert, was die Skalierbarkeit erhöht.
Wir erreichten damit die Entkopplung der Transaktionen vom ServiceBus-Kontext:
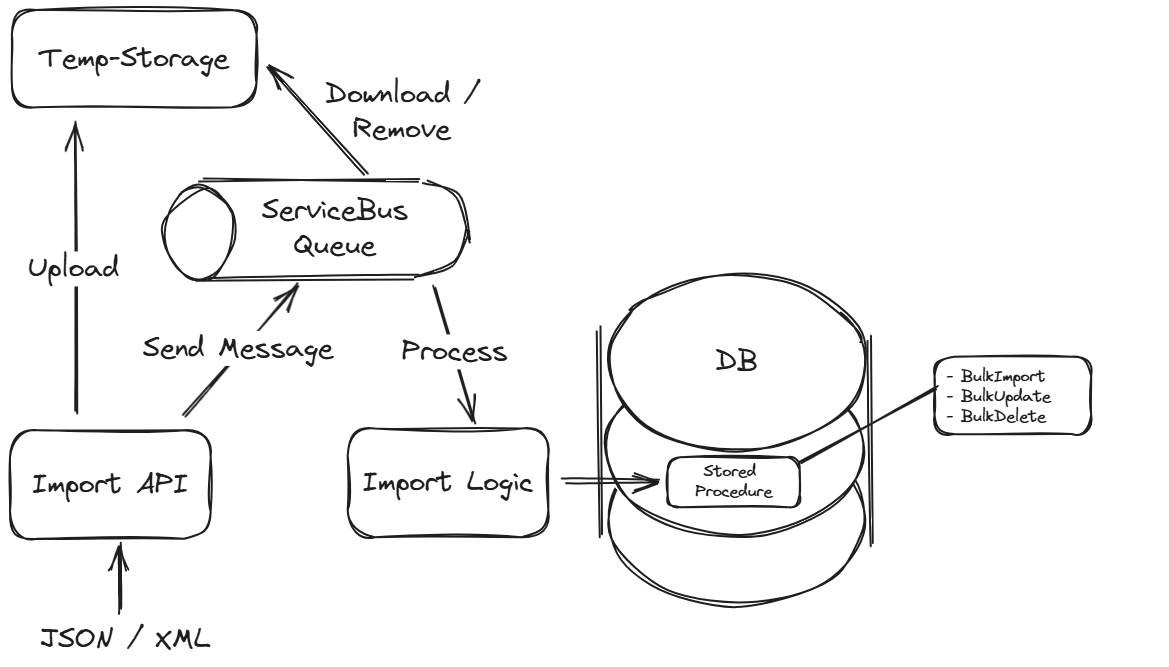
Das Anlegen kann aus dem Code heraus gemacht werden:
await Container.Scripts.CreateStoredProcedureAsync(procedure).ConfigureAwait(false);await Container.Scripts.ReplaceStoredProcedureAsync(procedure).ConfigureAwait(false);Die Implementierung des Aufrufs sieht wie folgt aus:
public async Task SaveToCosmosDb(MyData data)
{
var response = await container.Scripts.ExecuteStoredProcedureAsync<int>(
storedProcedureUri,
new PartitionKey(partitionKey),
new object[] { data });
}Die Ausführung von ExecuteStoredProcedureAsync geschieht immer innerhalb von Partitionen, was bedeutet, dass alle Operationen in einer Partition stattfinden müssen.
function myStoredProcedure(items) {
var context = getContext();
var collection = context.getCollection();
var response = context.getResponse();
var count = 0;
if (!items || !items.length) {
throw new Error("The items array is empty.");
}
// Rekursive Funktion zur Erstellung des Dokuments
function createDocumentRecursive(index) {
if (index >= items.length) {
response.setBody(count);
return;
}
var item = items[index];
var documentToCreate = {
id: item.id,
name: item.name,
createdAt: new Date().toISOString(),
};
var accepted = collection.createDocument(
collection.getSelfLink(),
documentToCreate,
function (err, documentCreated) {
if (err) throw new Error("Error: " + err.message);
count++;
createDocumentRecursive(index + 1);
}
);
if (!accepted) throw new Error("The stored procedure timed out.");
}
// Starte die rekursive Erstellung mit dem ersten Item
createDocumentRecursive(0);
}Diese Stored Procedure speichert eine Liste von Items in der Cosmos DB und gibt die Anzahl der erfolgreich erstellten Dokumente zurück. Die Verwendung von JavaScript ermöglicht es, komplexe Logik und Datenmanipulationen direkt innerhalb der Datenbank auszuführen, was sowohl die Effizienz als auch die Leistung verbessert. MIt createDocumentRecursive wird eine rekursive Funktion aufgerufen, welche die Dokumente in der Sammlung erstellt. Der index: ist der aktuelle Index des Items, das erstellt werden soll. Sie beinhaltet eine Überprüfung, ob der Index das Ende des Arrays erreicht hat. Wenn ja, wird die Anzahl der erstellten Dokumente (count) als Antwort zurückgegeben und die Funktion beendet.
Was hat's gebracht?
Ziemlich viel. Angefangen bei der immer wieder erfrischenden Erkenntnis, wie gut und wichtig der ungezwungene Austausch mit Kollegen ist, bis hin zu den Hard-Facts:
- Deutliche Performance-Steigerung. In Zahlen: 1/3 der vorherigen Import Dauer.
- Weniger Request Units und damit verbunden weniger Kosten
- Funktionelle Infrastruktur, die Datenintegrität gewährleistet.
Für mich war der Auf- und Umbau dieser Architektur ein Highlight in den letzten Monaten. Es war spannend zu sehen, wie wir Schritt für Schritt und dynamisch auf Änderungen der Anforderungen oder technischen Hürden reagieren konnten. Der gesamte Prozess verlief relativ reibungslos, was auf eine gute Planung und die Flexibilität unseres Teams zurückzuführen ist.
Das erste Implementieren und Testen einer Stored Procedure war straightforward, und die Erkenntnis der Vorteile und wie groß der Performance-Unterschied ist, war beeindruckend und motivierend für das gesamte Team. Wir konnten nicht nur unsere technischen Fähigkeiten erweitern, sondern auch wertvolle Erfahrungen sammeln, die uns bei zukünftigen Projekten zugutekommen werden.
Abschließend hat die Einführung von Stored Procedures nicht nur unsere technischen Abläufe verbessert, sondern auch unsere Gesamteffizienz gesteigert. Andere Imports und Bulk-Ausführungen in unserem System können langfristig auch von der Umstellung profitieren.