

Michael Silzle
Michael ist Softwareentwickler und Geschäftsführer von codeunity
15.12.2022 | 5 min Lesezeit
Metriken für das Monitoring von Cloud Services



Wer einen oder mehrere Cloud Services betreibt, muss sich früher oder später mit dem Monitoring solcher Services beschäftigen. Dadurch kann man frühzeitig erkennen, wenn einer oder mehrere Services nicht ordnungsgemäß funktionieren. Besonders herausfordernd wird das, wenn mehrere Services voneinander abhängig sind und beispielsweise sequentiell eine Aufgabe zusammen abarbeiten. Wenn ein Service fehlerhaft ist, muss dieser genau identifiziert werden können, um entsprechende Maßnahmen einleiten zu können. In diesem Post soll anhand eines Praxisbeispiels beleuchtet werden, welche gängigen Methoden es für das Monitoring gibt und wozu man welche Informationen gebrauchen kann.
Praxisbeispiel
In einer Microservice Architektur gibt es drei sequentiell arbeitende Services, die für Verarbeitung von MQTT-Nachrichten verantwortlich sind. Eingehende MQTT-Nachrichten werden dabei auf bestimmte Kriterien geprüft, validiert und zuletzt in einer Datenbank persistiert. Jeder Service hat eine andere Aufgabe. Wenn also einer der Services seine Aufgabe nicht oder nicht richtig durchführt, hat das Auswirkung auf die gesamte Verarbeitungskette. Die in der Datenbank persistierten Nachrichten werden in einer WebApp visualisiert.

Gehen im Worst Case bei der Verarbeitung Nachrichten verloren, wird das spätestens im UI bemerkbar. Um dies zu verhindern oder frühzeitig zu bemerken, sollen der Nachrichtenfluss und die Verfügbarkeit der Cloud Services überwacht werden.
Die bestehenden Cloud Services sind Java EE Applikationen, welche in OpenLiberty, einem leichtgewichtigen offenen Framework zur Erstellung von Cloud native Java MicroServices, gehostet werden.
Health vs Metriken
Prinzipiell wird zwischen dem Zustand (Health) und den Metriken (Metrics) eines Services unterschieden. Der Zustand beschreibt, ob der Service erreichbar ist und genügend Ressourcen zur Verfügung stehen. Ist der Zustand eines Services beispielsweise kritisch, kann dieser automatisch neu gestartet werden. Die Metriken geben hingegen detaillierte Auskunft darüber, wie gut ein Service gerade in Bezug auf Performance usw. arbeitet.
Klassischerweise werden sowohl Health- als auch Metrik-Informationen mittels einer REST-API bereitgestellt, auch bekannt als Health- und Metrics-Endpoint. Abbildung 2 verdeutlicht anhand der drei Services aus dem Praxisbeispiel den Unterschied zwischen der Health und den Metriken.
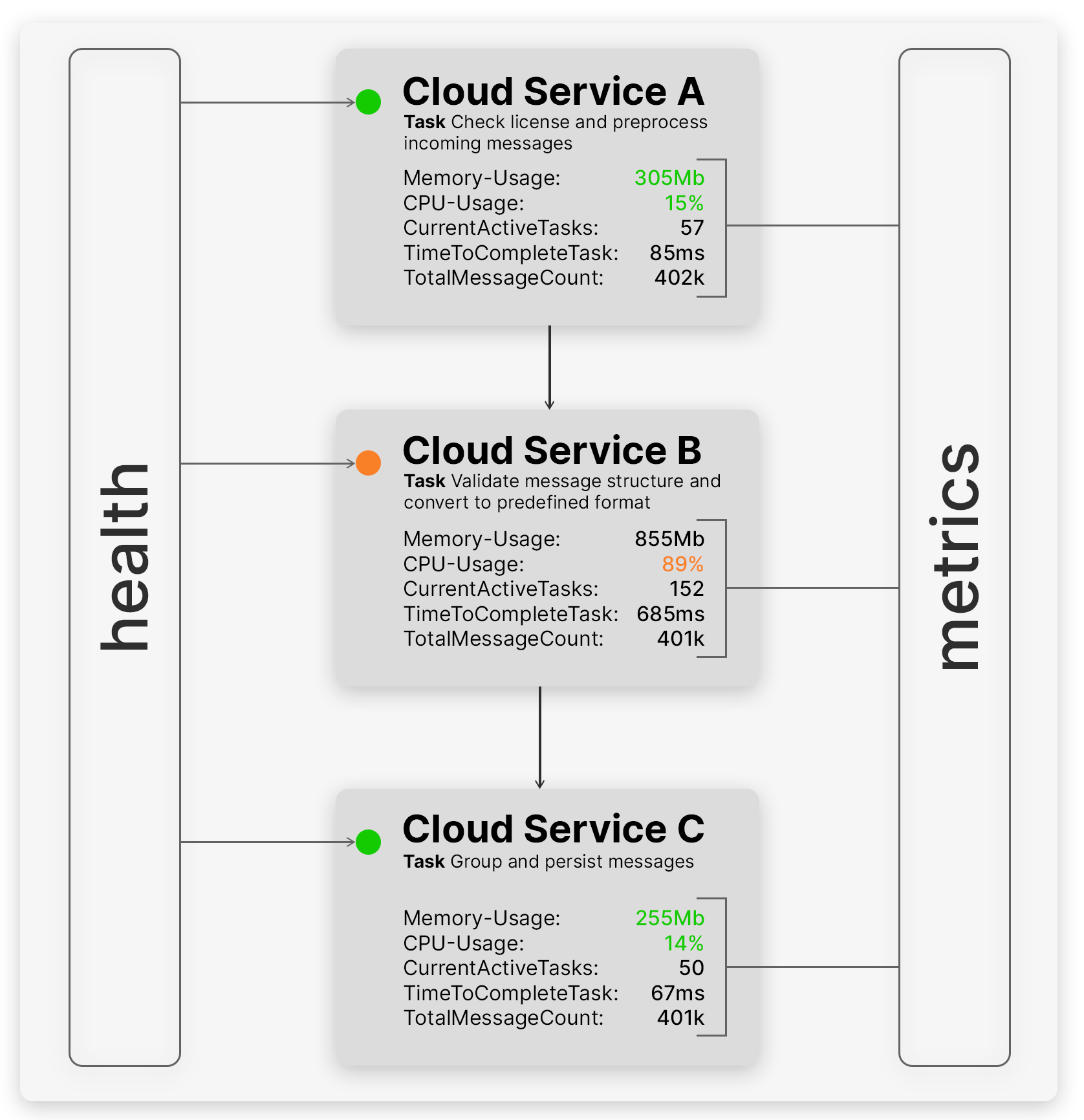
Hier wird erkennbar, dass die Health-Prüfung zwar beschreiben kann, dass jeder Service noch erreichbar ist, jedoch nur ein Blick in die Metriken Aussage geben kann, ob es einen Performanceengpass gibt oder Nachrichten nicht vollständig verarbeitet werden.
Die Standardmetriken wie CPU-Auslastung und Speichernutzung bietet nahezu jeder Webserver out of the Box. Diese können um eigene Metriken erweitert werden, was im Folgenden erläutert wird.
Festlegen der Metrik-Parameter
Da im Beispiel überwacht werden soll, ob Nachrichten ordnungsgemäß in allen Services verarbeitet werden, muss zunächst definiert werden, welche Parameter über den Metrik-Endpunkt bereitgestellt werden. Dabei eignen sich die Kennzahlen Anzahl eingehender Nachrichten und die Anzahl ausgehender Nachrichten. Für jede Metrik muss ein geeigneter Typ gewählt werden, da unterschieden wird, wie diese Werte weiterverwendet werden sollen. Für die Anzahl Nachrichten ist beispielsweise ein simpler Zähler (Metriktyp: Counter) ausreichend, der bei jeder Nachricht hochgezählt wird. Über die Differenz kann ermittelt werden, wie viele Nachrichten in einer gewissen Zeitspanne verarbeitet wurden. Für die Verarbeitungszeit je Nachricht eignet sich der Metriktyp Timer, da dieser eine Art Stoppuhr ist und die Dauer zwischen Start und Ende einer Aufgabe festhält. Nachfolgend eine Auflistung der gängigsten vier Metriktypen.
Gängige Metriktypen
- Counter Ein Integer Wert, welcher inkrementiert werden kann.
- Gauge Ein Integer Wert, welcher inkrementiert und dekrementiert werden kann.
- Histogram Ein Integer Wert mit Zusatzinformationen wie MIN, MAX, COUNT, AVG...
- Timer Gleich wie das Histogram, aber für zeitbasierte Kennzahlen.
Persistieren der Daten mit Prometheus
Die über den Metrik-Endpunkt bereitgestellten Informationen sind zur Laufzeit verfügbar und werden nach einem ReDeployment oder Neustart des Services zurückgesetzt, da diese nur InMemory verwaltet werden. Deshalb ist es notwendig, die Metriken mit Hilfe eines entsprechenden Monitoring Systems zyklisch abzurufen und zu persistieren, damit Auswertungen über eine Zeitspanne gemacht werden können. Dafür eignet sich populäre Prometheus, was sich ausschließlich mit dem Thema Metriken und dem Gewinnen von Erkenntnissen daraus beschäftigt, sehr gut. Mit diesem Tool hat man die Möglichkeit, langfristig und performant auf die Metriken zuzugreifen. Um bei Grenzwertüberschreitungen wie beispielsweise der Verarbeitungszeit benachrichtigt zu werden, gibt es E-Mail Alerts in Prometheus, welche mit dem AlertManager definiert werden können.
Prometheus ruft im Praxisbeispiel die Metrikendpunkte der Cloud Services im Intervall von 5 Sekunden auf und persistiert die bereitgestellten Informationen in einer Datenbank.

Für die Live-Anzeige der Daten kommt Grafana zum Einsatz, da dieses im Zusammenspiel mit Prometheus hervorragend funktioniert und viele verschiedene Diagramme für das Visualisieren der Metriken bietet.
Visualisierung mit Grafana
Die Prometheus eigene Query-Language ist vollumfänglich in Grafana integriert und kann Daten für die Anzeige und Auswertung aufbereiten. Mit wenigen Klicks kann man hier die Metriken in unterschiedlichen Chart-Typen, wie einem Zeitreihendiagramm oder einem Gauge, visualisieren, um ein Gefühl zu bekommen, zu welchem Zeitpunkt die Services wie viel oder wie gut gearbeitet haben. Zudem können die Metriken über einen ausgewählten Zeitraum korreliert werden, um Anomalien zwischen den einzelnen Metriken zu erkennen. Für das Praxisbeispiel wurde ein Dashboard in Grafana erstellt, mit dem man auf einen Blick die Nachrichtenzahlen der am Prozess beteiligten Services und deren Systemauslastung sehen kann.

Fazit
Mithilfe des Health-Checks, der Metriken und dem integrierten Alerting und der Visualisierung in Grafana steht die im Praxisbeispiel erwähnte Architektur auf einer soliden Basis und es konnten bereits Ausfälle frühzeitig erkannt und Gegenmaßnahmen eingeleitet werden. Gemessen am geringen Aufwand, den Health- und den Metrik-Endpunkt bereitzustellen und Prometheus und Grafana zu konfigurieren ist der Benefit, der dadurch entstanden ist, enorm.
In diesem Praxisbeispiel wurde die Umsetzung eines Service Monitoring mit Prometheus und Grafana in einem Java EE Umfeld gezeigt. Wer Grafana und Prometheus nicht selbst hosten möchte, kann das übrigens bequem über die Grafana Cloud als Hosted Service buchen.