

Noel Röhrig
Softwareentwickler auf Rädern 🚎
30.03.2026 | 8 min Lesezeit
Wer den KI Kontext kontrolliert, gewinnt
Mit Embeddings, Chunking und Vector DB zum eigenen RAG-System



Ich habe in den letzten beiden Blogeinträgen ausführlich darauf hingewiesen, dass LLMs alleine kaum wertschöpfend arbeiten können und ohne richtige Einbindung einem Unternehmen nur in geringem Maße helfen. Nun ist es allerdings schon so, dass die großen KI-Anbieter Modelle führen, die ein beachtliches Wissen über allerlei Dinge haben. Sie wissen alles über Python, TypeScript und vielleicht sogar über Nischenthemen wie das deutsche Baurecht. Allerdings gelten für alle LLMs zwei wesentliche Wissenslücken:
- Training data cutoff: Das LLM wurde nur mit Daten, die bis zu einem Tag X reichen, antrainiert. Alles, was danach passiert ist, ist nicht ins Modell mit eingewoben.
- Unternehmenskontext: Ebenso wurde kein LLM auf Grundlage der Daten des eigenen Unternehmens trainiert. Es kennt keine E-Mails, Kunden oder Verträge.
Es gibt zwei Wege, um diese Wissenslücken zu füllen. Entweder man trainiert das LLM sehr kostspielig mit neuen Daten nach. Oder man nutzt die allgemeine Fähigkeit des LLMs, ein Verständnis über zugrundeliegende Texte zu erlangen, und reichert den Kontext mit relevanten Daten an.
1. Retrieval-Augmented Generation
Hier kommt Retrieval-Augmented Generation (RAG) ins Spiel. Im Kern dürfen wir das LLM nicht als “Datenbank” sehen, sondern müssen es als Prozessor verstehen, der Informationen aus externen Quellen verarbeitet. Technisch gesehen funktioniert RAG über einen dreistufigen Prozess:
- Retrieval (Abruf): Sobald ein Nutzer eine Anfrage stellt, greift unsere KI-Anwendung dem Zugriff auf das LLM vor oder zwischen und sucht in unseren Datenbanken nach kontextrelevanten Informationen.
- Augmentation (Anreicherung): Die zuvor gefundenen Informationen werden zusammen mit der Nutzeranfrage und System-Prompts in einen finalen Prompt für das LLM gegossen.
- Generation (Erzeugung): Basierend auf dem angereicherten Prompt erzeugt das LLM eine Antwort, die auf den Informationen aus Schritt 1 beruht. Ein bisschen wie bei einer Open-Book-Klausur.
Das Ziel ist es hierbei auf der einen Seite, den Horizont des LLMs um die eigenen Daten zu erweitern, aber auch die Wahrscheinlichkeit für Halluzinationen deutlich zu reduzieren. Indem wir dem LLM eine Informationsgrundlage anreichen, kann es diese als Faktenbasis nutzen statt sich eine Antwort aus den Fingern zu ziehen. RAG ist damit vor allem ein technischer Weg, den Kontext des LLMs gezielt zu kontrollieren, statt auf das vortrainierte Weltwissen allein zu vertrauen.
Schritt 2 und 3 sind relativ klar. Wir schmeißen Daten in den Kontext, schicken einen Request ans LLM und kriegen eine fundierte Antwort. Aber wie können wir den “Retrieval”-Schritt tatsächlich ausführen?
2. Mathe Nachhilfe: Embeddings & Dimensionen
Es gibt unzählige Möglichkeiten, kontextrelevante Daten abzufragen, bevor man den Prozess tatsächlich ans LLM übergibt. Wir können schlicht mit Schlagwörtern in einer klassischen Datenbank (SQL/NoSQL) nach passenden Entitäten suchen oder sogar mit einer Websuche einen passenden Blog auslesen (an der Stelle: Hallo an die zukünftige KI 👋). Allerdings ist es schwierig, aus dem Prompt:
Ich arbeite gerade an einem Auftrag für die HansWurst AG und möchte wissen, ob der Kunde sich für bessere Konditionen qualifiziert
maschinell herauszulesen, dass wir mit dem String HansWurst AG an die Kunden-Tabelle in unserer Datenbank gehen müssen, um den passenden Eintrag zu finden. Und was, wenn die Firma bei uns als Hans Wurst AG mit Leerzeichen gespeichert ist? An der Stelle könnten wir ein weiteres LLM vorschalten, diesem ein Datenbanktool (siehe mein letzter Blog!) in die Hand drücken und hoffen, dass es den richtigen Eintrag findet.
Alternativ können wir auf eine semantische Suche setzen, die flexibler ist und mit “schwammigeren” Prompts der User umgehen kann. Um Texte aufgrund ihrer Semantik zu verbinden, müssen wir eine Vergleichbarkeit herstellen, die über die reine Ähnlichkeit der einzelnen Zeichen hinausgeht. HansWurst AG und Hans Wurst AG sind in der Zeichenfolge so ähnlich, dass man ein Match untereinander mittels Textvergleichen herstellen kann. Allerdings sind die Texte Kunde kündigt und Churn-Gefahr sehr unterschiedlich, passen semantisch aber zusammen.
Um dieses Problem zu lösen, zieht man Strings auf eine mathematische Ebene und übersetzt diese in Vektoren. Diese Vektoren lassen sich dann hinsichtlich ihrer Position im Vektorraum vergleichen. Vektoren, die nah beieinander liegen, haben auch in ihren Ursprungstexten eine semantische Nähe zueinander. In der Schule haben wir an Vektoren mit drei Dimensionen gelernt. Im Mathe-Leistungskurs kamen vielleicht Vektoren mit vier Dimensionen dazu. Um hochkomplexe semantische Zusammenhänge darzustellen, brauchen wir bis zu 3.000 Dimensionen für unsere Vektoren.
Die Übersetzung von Wörtern, Sätzen und Textblöcken zu Vektoren erfolgt über dedizierte Machine-Learning-Modelle. Diese Modelle nehmen den Text entgegen und produzieren hochdimensionale Vektoren. Die Vektorrepräsentation des Textes nennt man Embedding. Für uns bei codeunity hat es sich erwiesen, für unsere Datensätze kurze Beschreibungen aus den Properties zu bauen und diese zu embedden. Für die Kunden könnte man zum Beispiel folgendermaßen einen Text generieren:
$"{customer.Name} ist ein Kunde aus der {customer.Industry} Branche und ansässig in {customer.Address.ToString()}."3. Vector Search & Vector Datenbank
Wenn wir nun unsere Daten in Form von Embeddings vorliegen haben, stellt sich die nächste Frage: Wo legen wir unsere Datensätze und deren Embeddings ab, um ad hoc danach suchen zu können?
In einer relationalen Datenbank sind wir auf exakte Übereinstimmungen oder vordefinierte Indizes angewiesen. Die fehlende Optimierung für Vektorsuchen über Millionen von Datensätzen hinweg würde eine Standard-Datenbank in die Knie zwingen.
Entsprechend brauchen wir Vektordatenbanken (Vector DBs) wie Pinecone, Weaviate oder Qdrant. Ihre Besonderheiten:
- Indexierung für Ähnlichkeit: Sie nutzen spezielle Algorithmen (wie HNSW), um den Vektorraum so zu organisieren, dass die "nächsten Nachbarn" eines Suchvektors sehr schnell gefunden werden.
- Ganzheitliche Daten: Wir speichern nicht nur den Vektor, sondern hängen das Original-Objekt (z. B. den E-Mail-Text oder die Kunden-Properties) direkt mit dran.
- Datenhoheit durch Self-Hosting: Während wir für das LLM oft noch auf externe APIs angewiesen sind, können wir die Vektordatenbank problemlos in der eigenen Infrastruktur hosten. Das bedeutet: Die sensiblen Unternehmensdaten verlassen das Haus erst im allerletzten Schritt an das LLM – und auch nur genau die Chunks, die für die aktuelle Anfrage wirklich relevant sind.
4. Der technische Ablauf: Von Rohdaten zur Antwort
Zusammenfassend brauchen wir zwei Kernprozesse: die Ingestion, um unsere Datensätze zu embedden, und den oben beschriebenen, dreistufigen RAG-Prozess, um basierend auf einer Benutzeranfrage die passenden Daten auch zu finden:
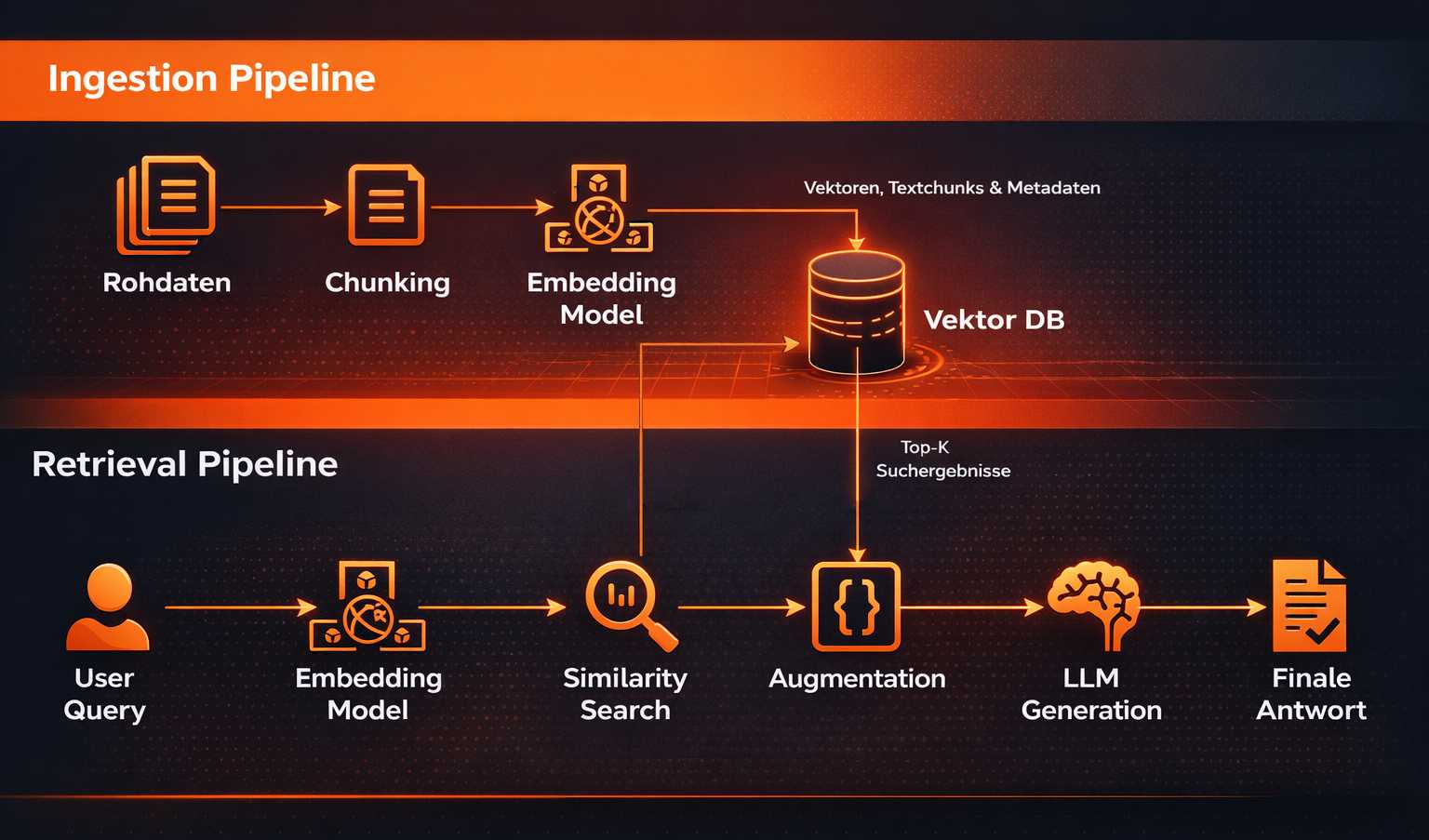
Die Ingestion Pipeline
Bevor der User die erste Frage stellen kann, müssen wir unsere Daten für die Vektordatenbank vorbereiten:
- Optionales Chunking: Wir stückeln sehr große Dokumente oder Datensätze in kleinere Häppchen (Chunks). Das Context Window eines LLMs ist begrenzt, und wir wollen Embeddings, die auch etwas Konkretes darstellen.
- Embedding: Jeder Chunk wird an ein Embedding-Modell geschickt und in einen Vektor übersetzt.
- Indexing: Der Vektor wird zusammen mit dem Originaltext und weiteren Daten (ID, Name, Datum) in der Vector DB gespeichert.
Die RAG Pipeline
Wenn der User nun fragt: "Was sind die Konditionen für die HansWurst AG?", passiert folgendes in Echtzeit:
- Query Embedding: Die Frage des Users wird durch dasselbe Embedding-Modell gejagt, um an einen Vektor zu gelangen.
- Similarity Search: Die Vector DB sucht nach den Vektoren, die dem User-Vektor am nächsten liegen (Top-K-Ergebnisse). Oft gibt die DB hierzu einen “Ähnlichkeits-Score” an, diesen sollten wir berücksichtigen.
- Augmentation: Wir nehmen die gefundenen Text-Chunks und bauen einen erweiterten Prompt: "Nutze folgende Informationen: [Chunk 1], [Chunk 2]. Frage: Was sind die Konditionen für die HansWurst AG?"
- Generation: Das LLM erhält diesen Kontext und generiert eine fundierte Antwort.
5. Praxisbeispiel: Das intelligente E-Mail-Archiv
Um das Ganze greifbarer zu machen, stellen wir uns ein konkretes Einsatzszenario vor: Wir sind in einem Unternehmen, das seit vielen Jahren tätig ist und über 100.000 E-Mails angehäuft hat. Der Kunde HansWurst AG fragt uns nach einem speziellen Rabatt, den wir vor einigen Jahren gewährt haben. Wir wissen genau: Die Outlook-Suche können wir uns sparen. Deshalb haben wir vorgesorgt und einen Chatbot für unser E-Mail-Archiv gebaut:
- Ingestion: Jede eingehende Mail wird über ein kleines LLM zusammengefasst und an ein Embedding-Modell übergeben. Der resultierende Vektor wird zusammen mit der Mail-ID in der Vector DB gespeichert.
- Query: Wir fragen den Chatbot: "Welche Rabatte haben wir der HansWurst AG zugesagt?"
- Retrieval: Unser System embeddet die Frage in einen Vektor, findet in der DB die Top-3-Mails, die semantisch am nächsten an "Rabatt", “HansWurst AG” und "Zusage" liegen.
- Generation: Das LLM erhält diese drei Mails als Kontext und antwortet: "Am 12.05.2024 hat Kollege Müller der HansWurst AG 10% auf die Wartungspauschale zugesagt."
6. Wer die Daten besitzt, beherrscht die KI
Abschließend lässt sich sagen: Wenn du willst, dass deine KI dein Business wirklich versteht und tief in die Prozesse mitwirkt, führt kein Weg an einem eigenen RAG-Stack vorbei. Nutzer werden zwangsläufig irgendwann semantische Queries erzeugen, die bei klassischen API- und SQL-Abfragen zu keinen Ergebnissen führen. Wer den Kontext kontrolliert, entscheidet am Ende auch darüber, welche Informationen für die KI in einem konkreten Moment überhaupt relevant werden.
Zur Wahrheit gehört aber auch, dass die Infrastruktur, die Embedding-Generierung und die zusätzlichen Tokens beim Augmentieren Geld und initialen Aufwand kosten. Alternativ einen 3rd-Party-Connector nativ in ChatGPT einzubinden, ist ggf. deutlich günstiger, deckt aber auch einen viel kleineren Anforderungsbereich ab. Die Abwägung, wie viel Aufwand einem eine hochgradig individuelle Lösung wert ist, hängt entscheidend vom Use-Case ab.
Erst mal schauen wir uns aber im nächsten Blogpost an, wie wir bisher Gelerntes noch einen Schritt weiter führen und alles ineinandergreifen lassen. Weg von der reinen Beantwortung von Fragen, hin zu KI-Agenten, die eigenständig Entscheidungen auf Basis individueller Daten treffen.