

Noel Röhrig
Softwareentwickler auf Rädern 🚎
06.05.2026 | 11 min Lesezeit
KI Agenten verstehen — Tools, Loops und Context-Engineering
Wie KI Agenten funktionieren und wie wir sie bauen



Knarre, Trenchcoat und eine Uhr mit Laser - macht das unser LLM zu einem KI Agenten? Schlängelt sich ein KI Agent durch die Bits und Bytes der digitalen Welt und kämpft gegen die Datenflut, um uns Wertschöpfung zu bringen? Natürlich trifft keins von beiden zu - ich möchte mit diesem Blogbeitrag helfen, KI Agenten zu verstehen und den Begriff zu entmystifizieren. Dazu werden wir das bisher Gelernte bündeln.
Wir haben bereits definiert, dass ein LLM nur wirklich wertschöpfende Beiträge liefern kann, wenn es mit Tools und ausreichend Kontext ausgestattet ist. Statten wir nun ein LLM mit Tools aus, reichern es mit einem Kontext über unsere Domain an und geben ihm ein konkretes Ziel, dann haben wir im Grunde schon einen KI Agenten erstellt. Simon Willison hat Agenten folgendermaßen definiert:
An LLM agent runs tools in a loop to achieve a goal.
Die Tools haben wir uns bereits näher angeschaut, der Loop steckt bereits in den meisten Frameworks und das Ziel geben wir über einen Prompt oder den Kontext rein.
Es ist also wichtig, sich wirklich zu verinnerlichen: KI Agenten sind keine autonomen Wesen, sondern ein schlanker Orchestrierungsmechanismus.
Manche gehen sogar so weit, dass sie ihre Agenten als ein schlichtes switch Statement in einer while Schleife definieren und Frameworks gänzlich meiden.
Workflow vs. Agent
Bevor wir tiefer in die Kernmechanik von KI Agenten einsteigen, bedarf es noch einer kurzen Klarstellung. Es hat sich eine begriffliche Nuance etabliert, die bei der geistigen Orientierung in diesem Thema hilft, und zwar die Unterscheidung zwischen Workflows und Agenten.
Ein Workflow kann als Vorstufe eines Agenten interpretiert werden. Ein LLM ist hier genau so mit Tools und Kontext ausgestattet, nur werden die konkreten Tools und Schritte über vordefinierte Code-Pfade aufgerufen. Ein Beispiel hierfür haben wir vor Kurzem erst implementiert. Der konkrete Use-Case war, Rechnungen umzubenennen und vorzusortieren:
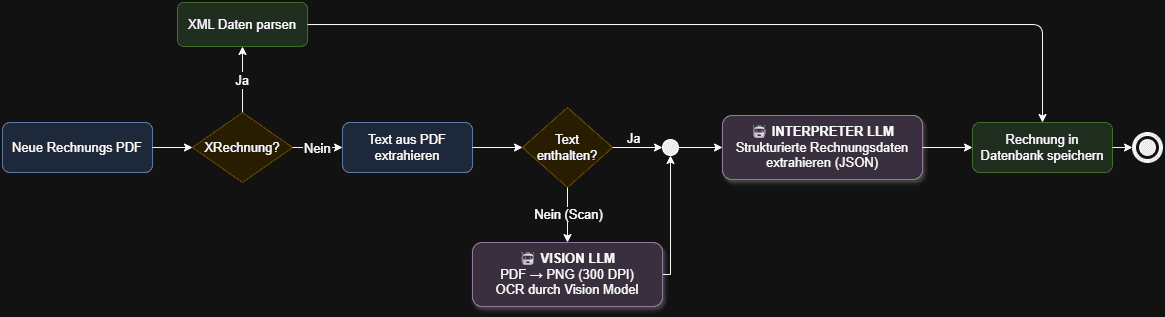
Wir setzen hier also ein LLM an zwei Stellen ein und diese sind auch mit Tools und System Prompts als Kontext ausgestattet - allerdings sind die Aufrufe in deterministischer, klassischer Software eingebettet und folgen einem klaren Code-Pfad. Die allermeisten KI-Anwendungen folgen derzeit diesem Prinzip.
Ein Agent hingegen, steuert seinen Prozess dynamisch und vor allem eigenständig: es gibt keinen deterministischen Code-Pfad, der entscheidet, wie lange der Agent arbeitet oder wie viele und welche Tools aufgerufen werden. Das macht diesen flexibel, aber auch weniger vorhersehbar. Bei unserem konkreten Beispiel von oben würde das bedeuten, dass wir das LLM mit noch mehr Tools ausstatten, die vorher einfach Teil des Code-Pfads waren. Das heißt, wir brauchen Tools für diese Schritte:
- Datei lesen
- Datei auf XRechnungsformat prüfen
- Datei als XRechnung auslesen
- Eintrag in der Datenbank erstellen
- Datei verschieben
- Dateinamen anpassen
Unser Agent wird dann von einer neuen Rechnung getriggert und kriegt über seinen Prompt das Ziel, diese einzusortieren und in der Datenbank zu pflegen. Den Weg dahin sucht sich das LLM aus.
Bevor man sich Hals über Kopf in die Implementierung eines Agenten stürzt: Es gilt, wie so oft im Leben, Keep it Simple, Stupid! Das obige Beispiel haben wir mit einem Workflow statt einem Agenten implementiert. Das ist schlicht die einfachere Implementierung, in dem Fall zuverlässiger und verbraucht weniger Tokens. Das ist auch die gängige Empfehlung von Anthropic.
Die Agent-Loops
Das, was ein LLM zu einem Agenten macht, ist nur das Gerüst, das wir um ein LLM herum aufbauen. Man spricht hier oft von einem Agent Harness - also dem Geschirr des LLMs. Hier liegt die eigentliche Engineering-Leistung für uns Entwickler. Wie eingangs beschrieben, ist das Herzstück des Harness der Loop, über den das LLM seine Aufgabe vorantreibt. Im Folgenden meine ich das Gerüst um das LLM, wenn ich über "Agenten" spreche - das LLM lässt sich beliebig austauschen und ist nicht Kern dieser Analyse.
Ein Agent besteht in seiner rudimentärsten Form aus vier Bestandteilen:
- Prompts: Die klassischen eingehenden Anweisungen an das LLM, die wir alle kennen. "Du bist ein [...], deine Aufgabe ist es [...], achte auf [...]"
- Tool-Routing: Wenn das LLM ein Tool aufrufen will, muss unser Code das entsprechende Tool auch aufrufen und den enthaltenen deterministischen Code ausführen. Salopp gesagt, gibts uns das LLM die response
toolA(parameter1)und unser Code muss mit der response über ein Switch-Statement das passende Tool aufrufen. - Kontext-Stapel: Ebenso muss der Kontext für die weiterführenden Aufrufe an das LLM immer weiter angereichert werden. Konkret muss die Response des LLMs, Tool A aufrufen zu wollen, als auch das Ergebnis des Aufrufs von Tool A in den Kontext geschrieben und damit das LLM erneut aufgerufen werden.
- Loop: Dieser ganze Mechanismus muss so lange wiederholt werden, bis das LLM das eigentliche Ziel als erfüllt betrachtet.
Die meisten dieser Komponenten werden durch Frameworks abgedeckt - auch wenn es hilft, sich einmal zu vergegenwärtigen, wie schlicht die Kernfunktionalität ist:
# --- 1. Prompt: Anweisungen an das LLM ---
system_prompt = """
Du bist ein Rechnungs-Agent. Dein Ziel: Lies die Rechnung, erstelle einen Datenbank-Eintrag,
benenne die Datei um und verschiebe sie in den richtigen Ordner.
Antworte mit DONE wenn du fertig bist.
"""
# --- 2. Kontext-Stapel: Akkumuliert über alle Schritte ---
context = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Neue Rechnung eingetroffen: {invoice_path}"},
]
# --- 3. Loop: Wiederhole bis das Ziel erreicht ist ---
while True:
response = llm.chat(context)
# LLM sagt "fertig" → Loop beenden
if response.type == "message":
context.append({"role": "assistant", "content": response.text})
break
# --- 4. Tool-Routing: Switch über den Tool-Aufruf ---
match response.tool_call.name:
case "read_file":
result = read_file(response.tool_call.args["path"])
case "create_db_entry":
result = db.insert(response.tool_call.args["data"])
case "rename_file":
result = rename(response.tool_call.args["old"], response.tool_call.args["new"])
case "move_file":
result = move(response.tool_call.args["src"], response.tool_call.args["dest"])
case "mark_success":
result = db.update(response.tool_call.args["id"], status="success")
case "mark_error":
result = db.update(response.tool_call.args["id"], status="error")
# Kontext anreichern: LLM-Entscheidung + Tool-Ergebnis
context.append({"role": "assistant", "content": response.tool_call})
context.append({"role": "tool", "content": result})Auch wenn das stark vereinfacht ausgedrückt ist, ungefähr so funktionieren Agenten (derzeit). Dieser zugrunde liegende Loop ist hardcoded (also deterministischer Code) und bei jedem Agenten gleich:
model generates → if tool call, execute it → feed result back → model generates again → repeat until the model returns text (no more tool calls)
Man nennt diese Kette den Inner Loop, also alles zwischen eingehendem Request und finaler Antwort. LLMs unterscheiden sich darin, wie sie diesen Loop navigieren und welche Entscheidungen sie darin treffen. Was der Agent innerhalb des Loops tut, welche Tools er aufruft, ist also die "Intelligenz" des LLM. Entwickler sollten auch immer Tools mitdenken, die dem LLM ermöglichen, Teilschritte auf Erfolg und Richtigkeit zu verifizieren. Falls etwas schief geht, ermöglichen wir dem Prozess dadurch eine Selbstkorrektur. Ein bewährtes Beispiel ist die Ausführung von Unit Tests durch Coding Agents. Der Agent entwickelt eine Softwarekomponente und prüft die Integrität/Richtigkeit durch die Ausführung von Unit Tests. Dieses Wechselspiel zwischen ausführenden Tools und der Verifikation des Ergebnisses nennt man Feedback-Loop.
So, damit haben wir aber jetzt genug Loops definiert, oder?

Falsch! Es verbreitet sich derzeit noch das Konzept des Outer Loop. Analog zum Inner Loop, der den Prozess einer Session oder Aufgabe des Agenten abdeckt, befasst der Outer Loop sich damit, die einzelnen Sessions nicht mehr isoliert abzufeuern, sondern über gespeicherte Notizen eine Art "Gedächtnis" für den Agenten aufzuspannen. Zugegeben: Der Begriff 'Loop' ist hier wahrscheinlich eher Marketing-Sprech, da es sich vielmehr um iterative Verbesserungen handelt, die sich aus Learnings vergangener Sessions bilden. Über Markdown-Files finden diese ihren Weg in den LLM-Kontext (Stichwort: MEMORY.md, SKILL.md, AGENTS.md, etc.).
Das einzige Problem an den Loops ist dasselbe wie mit allen Loops in der Softwareentwicklung: Wir laufen Gefahr festzustecken und den Prozess in einer Endlosschleife zu blockieren. Als Entwickler kennt man das vielleicht von seinen Coding Agents - in einer langen Session verliert sich der Agent und produziert keine guten Ergebnisse mehr. Manchmal bin ich dann so frustriert davon, dass ich es in einer neuen Session nochmal probiere - und da kommt das erwartete Ergebnis direkt. Genau da liegt das Context-Problem, das wir managen müssen. Über den effektiven Einsatz von Coding Agents und über Feedback-Loops hat Christoph eine tiefgreifende Analyse aufgezeichnet.
Micro Agents — Kleinteilig denken statt Universalisten bauen
Je mehr Schritte ein Agent durchläuft, desto voller wird sein Context Window — und desto wahrscheinlicher ist es, dass das LLM den Faden verliert. Dieses Phänomen nennt man Context Rot: Ab einem bestimmten Punkt sinkt die Fähigkeit des Modells, Informationen aus dem eigenen Kontext korrekt abzurufen. Ein Agent, der 50 Schritte hintereinander abarbeiten soll, kann irgendwann anfangen, sich im Kreis zu drehen oder bereits gelöste Teilprobleme erneut versuchen.
Zum Glück können wir dem etwas beikommen. Da KI-Anwendungen am Ende des Tages auch nur Software sind, gelten die gleichen Architekturprinzipien, die wir aus der klassischen Softwareentwicklung kennen. Genau wie ein monolithischer Service irgendwann unter seiner eigenen Komplexität zusammenbricht, scheitert ein monolithischer Agent an der Länge seines Kontexts und der Bandbreite seiner Tools. Der Ansatz: Micro Agents — spezialisierte, kleine Agenten mit klar abgegrenzten Aufgaben und einem Kontext, der auf 3 bis maximal 20 Schritte ausgelegt ist. Natürlich gilt hier, wie bei Microservices auch, die Warnung vor dem Over-Engineering - wir müssen eine Balance zwischen monolithischer Architektur und Modularisierung finden.
Der Haupttreiber für Multi-Agent-Architekturen ist dabei nicht unbedingt, dass ein einzelnes LLM die Arbeit nicht erledigen könnte. Es ist die Zuverlässigkeit, die durch Modularität entsteht. Ein fokussierter Agent mit fünf Tools und einem klaren Ziel liefert konsistent bessere Ergebnisse als ein Generalist mit dreißig Tools und einem schwammigen Auftrag.
Context-Engineering statt Prompt-Engineering
Selbst wenn wir unsere Agenten klein und fokussiert halten: Unsere mächtigste Waffe im Umgang mit LLMs ist das Context-Engineering. Kurz nach der Veröffentlichung von ChatGPT und zum Beginn des Hypes um künstliche Intelligenz machte der Begriff des Prompt-Engineerings die Runde. Dabei geht es darum, die Eingabeprompts an ein LLM so perfekt zu strukturieren, dass optimale Ergebnisse aus dem LLM purzeln. Im Grunde also nur Wortklauberei - Prompt-Engineering hatte aber in den frühen Tagen von limitierten LLMs mit kleinem Kontext auch seine Daseinsberechtigung.
Context-Engineering ist davon auch nicht so weit weg. Es ist nur die Evolution von Prompt-Engineering und bezieht die Dimension und Komplexität, die KI-Anwendungen erreichen, ein. Der Begriff hilft uns, den Scope, der bei einem KI Agenten relevant ist, mitzudenken. Und zwar den gesamten Kontext des LLMs: System-Prompts, Toolbeschreibungen, Tool-Ergebnisse, Konversationshistorie, externe Daten und vieles mehr. Wir müssen uns pro Aufruf des LLMs überlegen, was wir mit in den Kontext packen und was nicht.
Der Kontext ist bei allen LLMs eine begrenzte Ressource. Die üblichen Limits liegen bei den großen Anbietern bei 250k bis 1M Tokens. Eine Millionen Tokens entsprechen der gesamten "Herr der Ringe"-Reihe - inklusive dem Hobbit und Silmarillion. Da liegt es nahe, zu denken, dass man hier erst sehr spät auf ein Problem stößt. Leider ist der Kontext aber eine Ressource mit abnehmenden Grenzerträgen: Hier schlägt der bereits erwähnte Context Rot (auch Context Pollution genannt) zu. Mehr Tokens bedeuten nicht unbedingt bessere Ergebnisse.
Wir kämpfen konstant gegen einen zugrunde liegenden Zielkonflikt: Kontextgröße vs. Aufmerksamkeitsspanne des LLM. Wir wollen einen möglichst großen Kontext, der alle relevanten Informationen enthält. Gleichzeitig dürfen wir das LLM nicht mit zu vielen Tokens überladen. Zudem steigen die Kosten mit jedem Token. Es gibt Strategien gegen Context Pollution:
- Compaction: Konversation zusammenfassen und mit komprimiertem Kontext neu starten.
- Structured Note-Taking / Agent Memory: Agent schreibt sich Notizen außerhalb des Kontextfensters, liest sie bei Bedarf wieder ein.
- Just-in-time Data / RAG: Es werden nicht pauschal alle möglicherweise relevanten Daten zu Beginn in den Kontext geladen, sondern mit Tools erreichbar gemacht.
- Sub-Agents: Statt einem Agent, der alles tracken muss, spezialisierte Sub-Agents mit sauberen Kontextfenstern. Jeder Sub-Agent erhält einen konkreten Auftrag und liefert nur eine kondensierte Zusammenfassung zurück.
Fazit
KI-Agenten sind kein magisches Konstrukt, sondern die logische Konsequenz aus solider Software-Architektur: Tools, Kontext und Orchestrierung — zusammengeführt in einem Loop. Das Geschirr um das LLM herum, der Agent Harness, ist im Grunde klassische Softwareentwicklung.
Die eigentliche Engineering-Leistung liegt darin, dem LLM genau den richtigen Kontext zu geben und die Aufgaben intelligent aufzuteilen. Wer das beherrscht, baut zuverlässige KI-Anwendungen.
Mit codeunity sind wir Mitten drin in der Entwicklung — von KI-Workflows für klar abgegrenzte Aufgaben bis hin zu durchdachtem Context-Engineering für richtige KI Agenten. Die Technologie ist da, die Prinzipien sind klar. Jetzt liegt es an uns Entwicklern, sie solide umzusetzen.
Quellen
- Phil Schmid
- Simon Willison
- Anthropic: Agents
- Anthropic: Context-Engineering
- 12 Factor Agents
- Google Agent bake off
- IntuitionLabs Context-Engineering